
par Philippe Cosentino
La banalisation de l’usage des images médicales en classe
Avec l’arrivée de logiciels tels qu’EduAnatomist puis, récemment, d’EduAnat2, l’exploitation d’images médicales en classe s’est banalisée. C’est une bonne chose pour une matière telle que les SVT, qui doivent être ancrées le plus possible dans le réel ; or c’est bien le cas lorsque l’élève observe des IRM montrant des tumeurs ou les conséquences d’un AVC.
Mais cet ancrage dans le réel est tel qu’il présente un risque : ce sont à des cas cliniques bien concrets auxquels les élèves sont confrontés.

Capture d’écran du logiciel EduAnat2 montrant une tumeur située dans le lobe occipital
L’incontournable consentement du patient
Bien entendu, ces images ont été obtenues dans le respect des lois, et des règles de bioéthique. Un consentement écrit du patient est indispensable, et l’utilisation des images obtenues doit se faire dans des limites définies de manière très strictes.
A l’heure du RGPD, rien ne peut être laissé au hasard en matière de respect de la vie privée, et de collecte d’informations sensibles. Ces nouvelles réglementation ont freiné l’acquisition de nouvelles images et on comprend mieux pourquoi la mise en place d’une banque d’images médicales comme AnaPeda a nécessité une étroite collaboration entre les services juridiques du CHU de Nice et de l’ENS de Lyon.

Extrait de la déclaration de consentement que le patient doit remplir
Une anonymisation indispensable
L’une des précautions élémentaire que l’on doit prendre lorsque l’on crée du matériel pédagogique avec des IRM de vrais patients est d’anonymiser ces derniers. Toutes les précautions doivent être prises, pour que personne ne puisse remonter au patient à partir du fichier IRM. Tel patiente ayant autorisé l’utilisation de son IRM des ovaires ne souhaite probablement pas que tous les élèves de France connaisse son nom, son adresse, ses antécédents médicaux, etc.
Des métadonnées très sensibles
Or toutes ces données sensibles sont présentes dans les métadonnées des fichiers ou dossiers d’imagerie médicale !
Ils sont d’ailleurs facilement accessibles dès lors qu’on dispose d’un logiciel permettant d’afficher de telles images (à l’exception d’EduAnat2, où nous avons fait le choix de ne pas en permettre l’affichage).
Dans cet exemple, une IRM d’oreille interne au format DICOM que m’a envoyée une collègue (afin que je l’incorpore dans la base de données AnaPeda), il m’a suffi, après avoir chargé le fichier dans un logiciel d’imagerie, de cliquer sur un simple bouton « Metadata » (métadonnées en anglais) pour accéder à une quantité impressionnante d’informations concernant la patiente : son nom complet, sa date de naissance, son âge (ici 41 ans), sa masse, le nom de son médecin, l’adresse de l’hôpital, les problèmes de santé pour laquelle elle consulte etc.

Capture d’écran de la fenêtre « Metadata » du logiciel Slicer
Bien entendu, on y trouve également un tas d’informations utiles, telles que la pondération utilisée, T1 en l’occurrence, la puissance de l’aimant (3Tesla) la résolution, les corrections apportées etc., mais ce n’est pas l’objet de cet article.
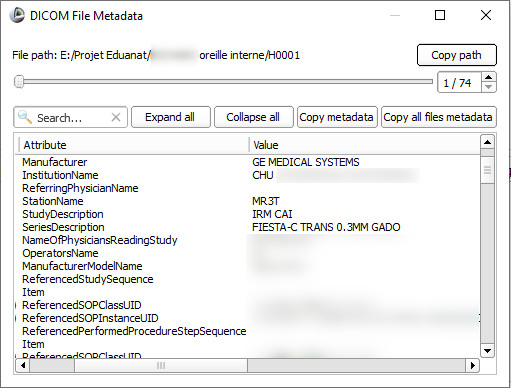
Capture d’écran de la fenêtre « Metadata » du logiciel Slicer
Prudence avec les métadonnées
Dans le cas des fichiers de la banque « AnaPeda », utilisés dans EduAnat2, toutes ces métadonnées indiscrètes ont été effacées du fichier. L’élève n’a aucun moyen de remonter jusqu’au patient.
Cependant, le cas s’est déjà présenté au moins une fois, où un collègue maladroit a souhaité faire travailler ses élèves sur une IRM de son genou avec un logiciel autre qu’EduAnat2 (qui n’affichera jamais les métadonnées). Au final, rien de bien grave, mais ses élèves ont rapidement pu déterminer la date de naissance de leur professeur, sa masse, et peut-être d’autres petits détails concernant la santé de son genou. Si cela avait concerné un élève (les élèves proposent parfois à leur professeur, dans un élan louable, des CD de l’IRM de leur dernière fracture), et que les parents en avaient eu vent, des poursuites auraient peut-être suivi la « fuite » de ces métadonnées.
Un problème qui ne concerne pas que les fichiers IRM
Il n’y a pas qu’avec les IRM que les métadonnées posent un problème vis à vis de la vie privée.
Le moindre document issu d’un logiciel de traitement de texte ou d’image comporte généralement le nom complet de l’auteur dans ses métadonnées. Il est important de le garder en tête lorsque l’on distribue un document que l’on souhaite garder anonyme. A l’inverse, diffuser un document créé par un élève posera le souci de la divulgation de son nom complet.

Capture d’écran des « propriétés » d’un fichier créé par Word
Pire : avec la banalisation de la géolocalisation, la moindre photographie prise à partir d’un téléphone (notamment par nos élèves) contient dans ses métadonnées les coordonnées de la prise de vue. Un élève peut ainsi, en diffusant une photographie, rendre publique les coordonnées de sa maison, de son école, en plus de son nom complet.
Dans le cadre de l’enseignement de SNT, en classe de 2de, les élèves sont fortement sensibilisés à ce problème, dans au moins 3 des 7 chapitres (géolocalisation, données structurées, photographie numérique …). C’est une bonne chose, mais cela signifie également qu’ils seront plus regardant concernant les données et métadonnées que nous diffusons à partir de leurs travaux. Il convient donc d’être très prudent.
On rappelle également que la compréhension des métadonnées fait partie du référentiel CRCN qui encadre l’évaluation des compétences numériques (domaine « Informations et données », compétence niveau 5 « Comprendre les métadonnées et leur
fonctionnement »).

Coordonnées de prise de vue dans les métadonnées EXIF d’une photographie
Des données également sensibles
Pour terminer, et pour en revenir aux données médicales, on pourrait penser, que seules les métadonnées permettent de remonter au patient. Il n’en est rien.
Les données des IRM et scanographies elles-mêmes présentent un problème potentiel. En effet, à partir des « tranches » d’une IRM, il est très facile de reconstituer le visage du patient dans ses 3 dimensions. Dans certains cas, le résultat est si précis, que ce visage est facilement reconnaissable pour un familier du patient. C’est l’une des raisons qui nous ont poussé à réduire la résolution des modèles tridimensionnels de tête dans EduAnat2.

Reconstitution (très floutée) du visage du sujet 13231
Avec le développement de l’intelligence artificielle et de la reconnaissance faciale, on peut raisonnablement penser que dans un avenir proche, une application serait capable d’identifier un visage « reconstitué » et donc d’associer un nom à un fichier IRM dont les métadonnées auraient pourtant été anonymisées. La réalité pourrait rapidement rattraper la science fiction en ce domaine !
Liens
Lien vers la banque AnaPeda sur le site de l’ENS de Lyon
Autres articles en lien avec les TRAAMs 2019-2020 sur les métadonnées
